
Canva AI 課程上線


有沒有這種經驗:明明只是要完成一份 Canva 的內容,可能是簡報、貼文、提案頁面或活動素材,結果在 Canva 上面使用既有的版本或是 Canva AI 的功能,從想架構、寫文案、找素材、做視覺到反覆調整,卻發現不管怎麼做都還是不夠滿意。
其實呀,如果 Canva 既有的功能跟 Canva AI 已經無法滿足你的話,不如我們換一個角度來思考:把 Canva 當作一個應用平台,試著導入「數位工具協作的工作流」:把不同工具放在它最擅長的位置,讓產出變快、變穩、也更容易複製。

像我自己在課程中就會提到,我將不同的數位工具分成三類:分別是任務助理、應用助理以及靈感助理。而 Canva 在這之中的角色就是協助我將想法落地的平台。當我真的需要解決特定任務,或者是尋找創意靈感的時候,都會試著導入其他的工具來做結合。
這篇文章我帶給你一個全新的思考切入點:以 Canva 平台為核心,接著結合主流的生成式 AI 工具導入進 Canva 的工作流程,讓你更加提高製作效率以及成果效益。
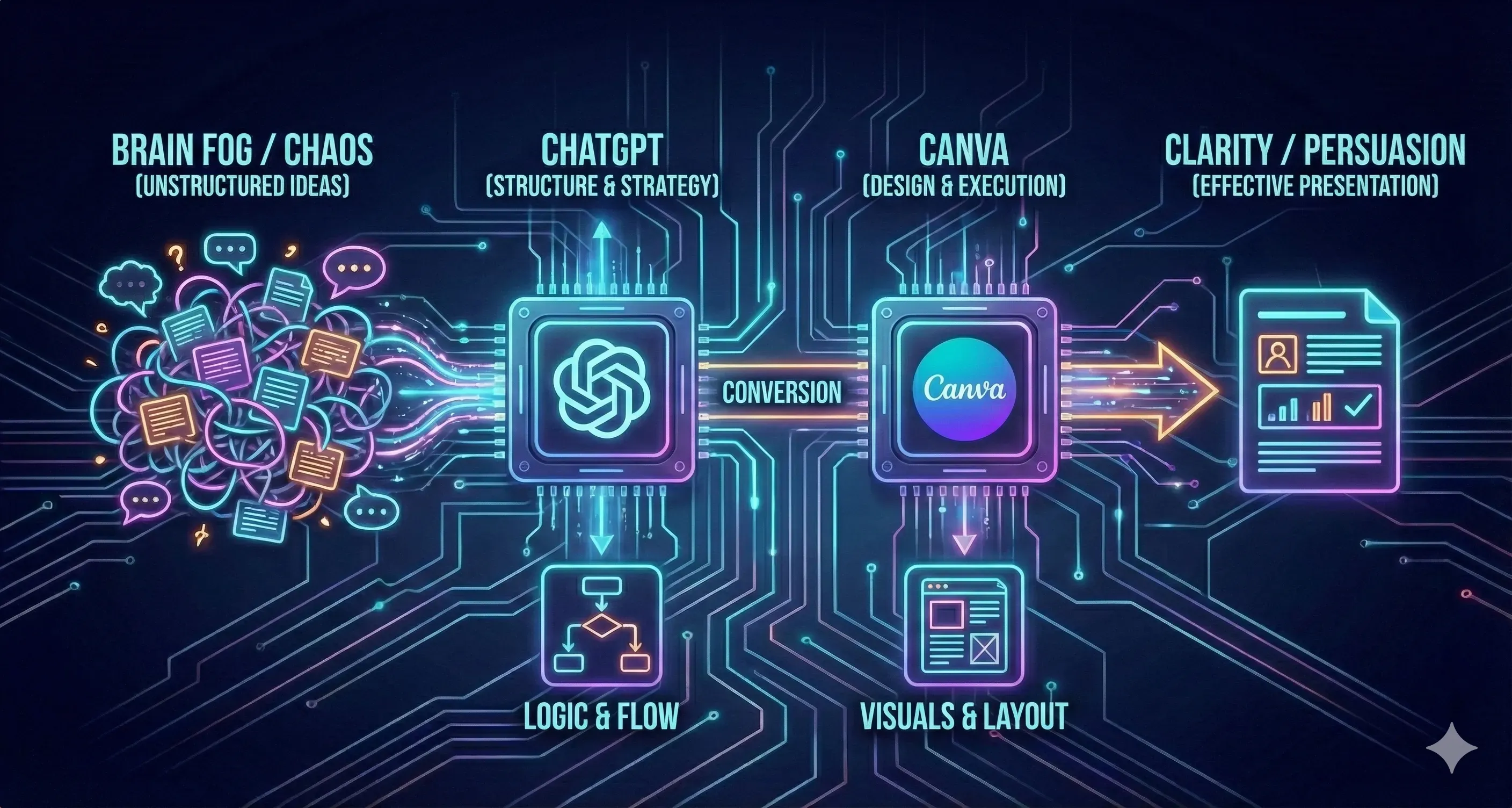
當你要製作簡報時,最常卡住的不是資料不夠,而是腦中有很多想法卻不知道怎麼排成「合理、好懂、能說服」的順序。你可能知道要講什麼,但不知道該先講背景、先丟痛點、還是先講結論;也可能每一頁都想放,最後反而變成資訊堆疊、重點失焦。
這種時候若直接在 Canva 用「魔法文案」產出文字,很容易得到看起來完整、但邏輯與節奏不夠精準的內容;相對地,先在 ChatGPT 把架構與敘事策略談清楚,再回 Canva 套版與落地,會更有效率也更穩。
【情境敘述】
我正在準備一份【主題】簡報,受眾是【受眾】,預計呈現時間【X 分鐘】或頁數【X 頁】。我目前卡在「架構與內容順序」:我有一些素材 / 想法【簡述你已有的資料或重點】,但不知道該怎麼排才會清楚、順、好說服。
【任務講解】
請你扮演我的「簡報內容策略顧問」,先提出 2~3 套不同的架構路線(每套要有清楚的敘事邏輯),並說明各自適合的使用情境並且展開成逐頁大綱,讓我可以直接搬進 Canva 製作。
【格式補充】
請按以下格式輸出:
A. 目標理解(1 句)
B. 架構方案(2~3 套):每套列出頁面順序+每頁目的(用 1 句說清楚)
C. 我應該如何選(用 3 句比較:各方案優缺點+適用情境)
D. 逐頁大綱輸出格式:每頁包含「頁標題 / 3 個要點 / 一句話講稿 / 建議呈現形式(清單、流程、對比、案例、數據)」
限制:避免空泛形容詞;每頁要點精簡可貼進簡報。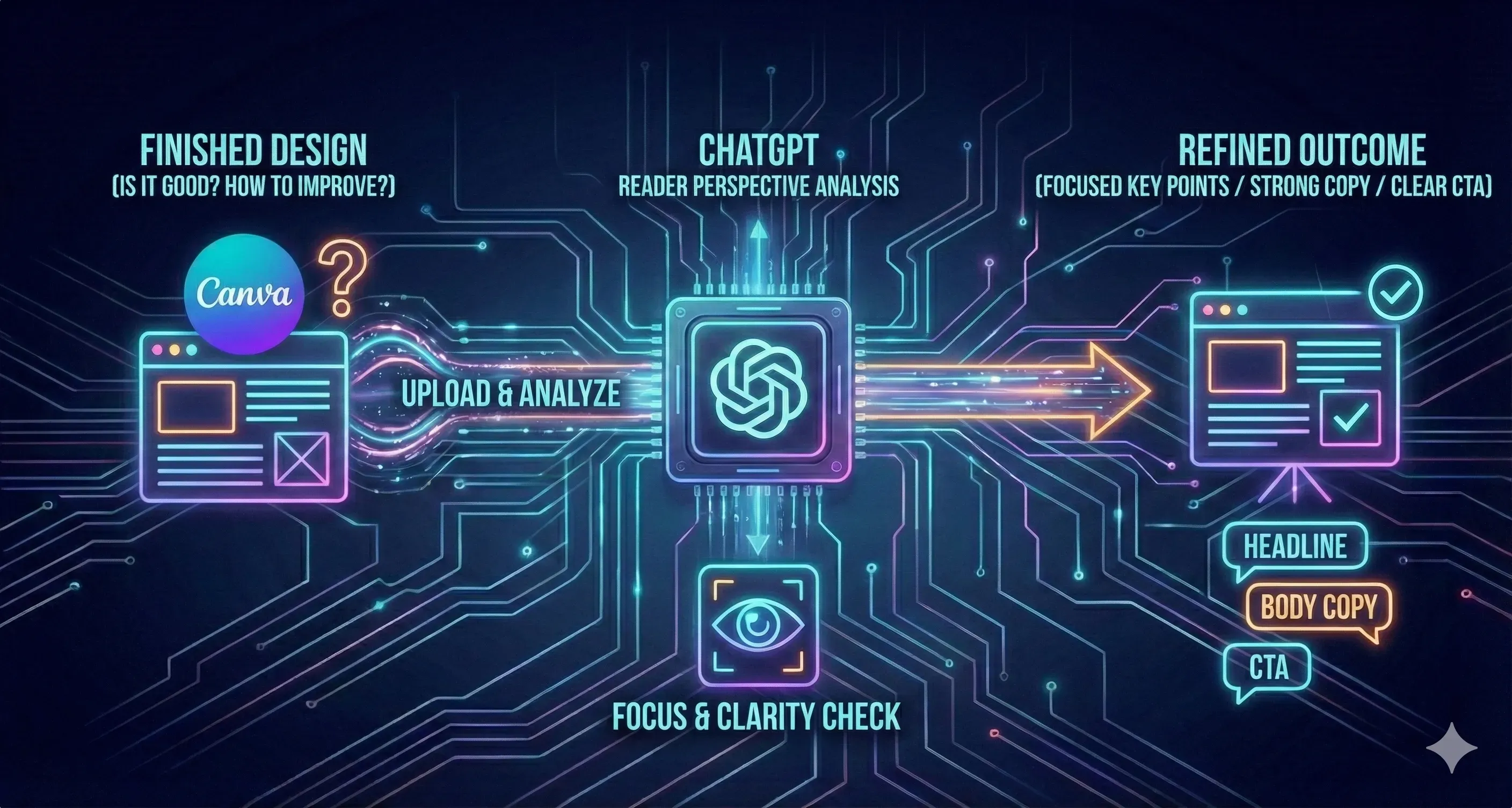
當你在 Canva 已經完成一張圖或一份簡報後,常見的困擾不是「做不出來」,而是「不知道它到底好不好、還能怎麼更好」。
你可能覺得訊息有點不夠聚焦、讀者第一眼不一定抓得到重點,或者你要把海報 / 社群圖發布出去時,突然卡在貼文怎麼寫、標題怎麼下、CTA 要怎麼收。這時候把成果直接貼給 ChatGPT,讓它用「讀者視角」來健檢與提供文案策略,通常比你自己盯著畫面想半天更快、更有方向。
【情境敘述】
我會貼上一張我在 Canva 完成的【簡報頁/海報/社群圖】圖片。它的目的主要是【曝光/點擊/報名/購買/說服】;受眾是【受眾】;發布渠道是【IG/FB/LinkedIn/投影片/活動頁】。我想確認這個成果是否清楚、有吸引力,並且需要你協助我規劃發布文案。
【任務講解】
請你用「讀者第一次看到」的角度幫我做健檢,指出訊息是否清楚、重點是否突出、是否有誤讀風險,以及若要提高【我的目標】應該怎麼調整。接著請直接產出多版本文案,讓我能快速選用與迭代。
【格式補充】
請按以下格式輸出:
A. 第一眼讀到的重點(1 句)+可能誤讀點(若有)
B. 優化建議(3 點):每點都要包含「問題 → 建議改法 → 改完期待效果」
C. 文案套組(提供 3 組):每組包含「開頭鉤子 1 句 / 主文 80–120 字 / CTA 1 句 / Hashtag
D. 修改方向(2~3 個):例如更精簡、更強行動、更專業、更口語(給具體改寫規則)
限制:不要空泛稱讚;文案避免過度誇大;CTA 要明確可執行。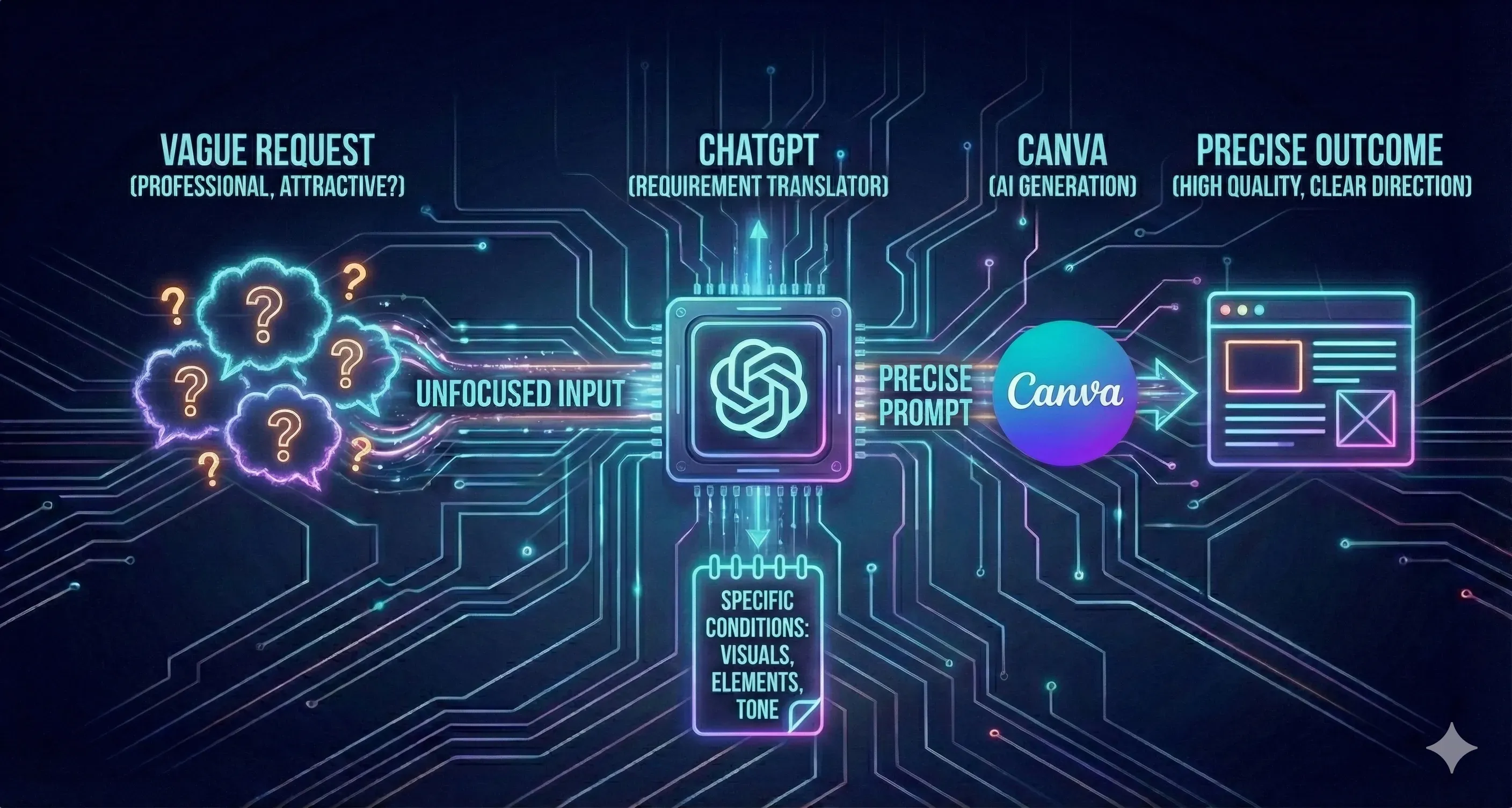
Canva 內建很多 AI 功能,但效果好不好,常取決於你下指令是否具體。如果你的需求停留在「更專業、質感一點、吸睛一點」,AI 很容易給出「合理但不對」的結果,最後你花更多時間來回修改。
這時 ChatGPT 的價值不是取代 Canva,而是先把需求翻譯成可執行的條件:輸出要長什麼樣、要包含哪些元素、要避開什麼、語氣要怎麼拿捏,然後把一段精準 Prompt 交回 Canva 使用,成品的質感通常會直接升級,而且更有修正方向。
【情境敘述】
我要在 Canva AI 使用【功能名稱:設計、圖像、程式碼、影片片段】、受眾是【受眾】、我希望結果符合【品牌調性/限制】並避免【不想出現的內容或用字】。
【任務講解】
請你扮演「Canva 指令撰寫助手」,幫我寫出一段可以直接貼到 Canva 的提示詞,讓 Canva AI 更容易產出符合我需求的結果。同時請提供可快速調參的方向,讓我不用重寫整段指令也能迭代。
【格式補充】
請按以下格式輸出:
A. 你理解的輸出目標(1 句)
B. 讓我「可直接貼進 Canva」的提示詞(繁體中文),提供的邏輯同樣按照「前情敘述、任務講解及格式補充」這樣的方式)
限制:提示詞要具體可執行;避免大量形容詞;明確定義輸出格式(例如條列、段落、JSON 欄位或固定段落結構)。你會遇到的狀況通常是這樣:你已經在 Canva 選好一個簡報封面範本,版面結構很適合,但範本裡的元素或照片「跟你的主題 / 情緒 / 想傳達的質感不對盤」。你也試過用 Canva AI 直接生成,結果不是風格跑掉、就是細節不到位,最後反而浪費更多時間在「將就」或「修到看起來像對的」。

這時最有效的做法是把工作切開:範本留在 Canva,主視覺交給 Midjourney,用更擅長 AI 生圖的模型先把想要傳達的客製化畫面生成到位,再回 Canva 直接替換,一次把質感拉起來。
【情境敘述】
我正在製作一張【簡報主題】的封面主視覺,整體情緒是【沉穩/科技/溫暖/高端/年輕…】,並符合【品牌調性/產業】,我用 Midjourney 生成一張貼近我的需求、質感更到位的封面圖片。
【任務講解】
請你幫我寫出「可直接貼到 Midjourney」的封面圖片提示詞,目標是生成一張符合主題與情緒、且能刻意留出文字空間的主視覺。請同時提供兩個版本:一個「保守穩定版」與一個「更有記憶點版」,但兩者必須維持相同核心風格與主題。
【格式補充】
請用以下格式輸出:
A. 你理解的封面需求(1 句:主題+情緒+構圖留白需求)
B. Midjourney 提示詞(穩定版,1 行可直接貼上;包含主體、場景/材質/光線、風格、構圖指令、留白指示、比例參數 --ar)
C. Midjourney 提示詞(記憶點版,1 行可直接貼上;同上但更具特色)
D. 避免事項(3 條,要具體:例如避免文字出現在圖上、避免臉部特寫、避免背景元素過雜)你會遇到的狀況通常不是「做不出影片」,而是「找不到剛好符合主題、風格一致、又能配合範本節奏」的動態素材。尤其當你想做的是某種特定氛圍(更科技、更夢幻、更擬真、或更插畫感),Canva 的素材庫可能沒有剛好對應的片段。
這時候 Midjourney 的價值在於:你可以把素材變成「可客製化」的!要嘛拿你在 Canva 找到的參考素材去做風格轉換並生成影片,要嘛先生成符合你想法的圖片,再把圖片延伸成動態,讓整體呈現更一致(這邊同步 MJ V1 模型的概念影片)。
Midjourney 的 V1 影片模型採用「Image-to-Video」工作流:你先準備一張圖片(可以是你在 Midjourney 生成的,也可以是你自己上傳的),把它指定為影片的起始畫面,接著用 Animate 生成影片。
文字提示詞在這裡是「可選」:你可以不寫,讓系統自動給一個「讓畫面動起來」的 motion prompt;也可以改用手動(Manual)自己描述要怎麼動、鏡頭怎麼走、氛圍怎麼變。

關於 Midjourney 的操作,其實有非常多可以教學的內容,日後有機會的話,再額外寫獨立的一篇來做教學。
先在 Nano Banana 把流程圖的整體視覺與風格一次生成出來,等於先拿到一張漂亮又一致的底稿,再回 Canva 去做元素比例微調、文案修正、加上品牌元素,效率會高很多。
但目前 Nano Banana Pro 不能像投影片那樣逐字改;如果你要把文字拆成可編輯物件,可以在 Canva 用 Magic Studio 把文字抓出來,但效果會視字體、對比、排版而定()。
Canva 的修圖工具很方便,但遇到比較「刁鑽」的需求(例如:要保留原本質感、但只改某個細節;或要做一系列一致的修圖變體),結果可能會出現不自然、細節跑掉、或改了 A 壞了 B 的情況。


這時候把圖片先拉到 Nano Banana,用更明確的自然語言去描述「只改哪裡、其他都不要動」,反而更容易精準達成你要的效果;修好之後再放回 Canva,繼續做排版、加字、輸出即可。
同樣的,關於 Nano Banana 的操作有非常多的應用情境。日後有機會的話,會再獨立寫一篇來做教學(各種挖坑給自己跳🤣)

當你開始把 Canva 視為「成果落地的平台」,而不是從思考到創作的唯一入口,整個製作流程就會明顯鬆開。把架構與策略交給 ChatGPT、把關鍵視覺交給 Midjourney、把精修與流程圖交給 Nano Banana,讓每一個 AI 工具各司其職,Canva 才能發揮它真正擅長的價值。
這不是在學更多工具,而是在建立一套可複製、可放大、也更穩定的 AI 協作工作流。當你不再硬撐在 Canva 裡想完所有事情,創作這件事,反而會變得更快、也更好。
因為 Canva AI 擅長「快速執行」,但不擅長「做得精緻」。如果説你在下指令時並沒有良好的架構、受眾與目標還沒釐清前就直接要求它生成內容,結果通常完整但不精準,容易看起來不够精致且不夠有說服力。
ChatGPT 負責思考層(受眾、邏輯、敘事、文案策略),Canva 負責呈現層(版型、視覺、排版與輸出),把「想清楚」跟「做出來」分開。
當你在 Canva 找不到符合主題、情緒或品牌質感的主視覺時,Midjourney 非常適合用來生成封面圖、主視覺或動態素材,再回 Canva 套用範本,質感會直接升級。
可以!但因為要套用Canva的範本的話,要記得留意圖片生成的比例、解析度與是否有足夠的留白空間做發揮。最好的方式是,在 Midjourney 生成時就先規劃好構圖,回 Canva 後只需要替換圖片與微調視覺即可。
因為多數使用者下的指令過於抽象(例如:更專業、更有質感、更吸睛),這些描述對 AI 來說缺乏可執行條件。透過 ChatGPT 先將需求轉譯成具體限制(構圖、元素、比例、風格、避免事項),再交給 Canva AI,生成結果通常會更貼近實際需求,也更容易微調。
Canva 魔法工作室強在「快速」,Nano Banana 則強在「精準控制」。當你需要只修改特定區域、維持整體質感不變,或生成一致風格的流程圖時,Nano Banana 會更穩。
短期會,但中長期反而能大幅降低重工成本。一旦你建立固定的角色設定、指令模板與判斷流程(例如:何時用 ChatGPT、何時用 Midjourney),每一次專案都能快速複製流程,而不是從零思考怎麼開始。
本篇文章著作權人:PPT.note 簡報仙貝
未經正式授權,請勿任意轉載。
從 2016 年開始做簡報培訓,直到 2022 年開始開辦各種 Canva & AI 工具工作坊的我們,決定在 2025 年底把最好用的一套流程打包給你!
我們近期推出的【Canva AI 線上課程】!將帶著你把 Canva 的製作效率,和一票強大的 AI 工具串在一起:從發想、找素材、定版、到視覺優化,一路開掛到讓你懷疑之前加班這麼辛苦是為了什麼😎
Canva 看起來人人都會用,但關鍵在於帶入「品牌思維」、「功能整合」與「場景活用」
這堂課在分享功能以及 AI 工具時,只會挑一條我們認為最好走的路。透過 Canva 作為產出的中樞,再結合 AI 工具讓你把效率拉滿。從今天起不用再當工具收藏家,直接當大量的視覺成果製造機😉
讓你把 Canva 和 AI 串成真正的生產線!
哈囉你好!我們是 PPT.note 簡報仙貝,由兩位對 PPT、Keynote、Excel 及 Canva 等軟體感興趣的夥伴共同經營,我們在 2021 年正式成立,目前在 Instagram 上有 11 萬粉絲與我們共同學習,我們將會於網站及社群上,繼續分享更多簡報技巧及實用的辦公軟體知識!
– Canva AI 操作全攻略|用 AI 產生設計、圖片、文件、程式碼與影片片段
– Canva 魔法工作室全攻略?用 AI 去背、修圖、去雜物、文案及翻譯的新手指南
– 一人公司必學 Canva 工作流:用 Canva 打造內容與設計加速流程
– Canva 套版到客製化版型:AI VIBE 心法,新手也能做出高質感設計
– Canva Code x Canva 網站:3 種互動遊戲應用與網站功能差異比較
– ChatGPT:https://chatgpt.com
– Midjourney:https://www.midjourney.com
– Gemini:https://gemini.google.com



